Endless Scrolling
My app lets you search for movies by title. The Open Movie Database API will return only ten titles at a time. So my first attempt filled a list with the first ten titles from a query, then rendered a set of pager buttons at the end of the list. The user could press the “Next” button to request another ten titles. Once the next set was displayed, the user could continue forward or go backward. There were also buttons to fast-forward to the last page, or rewind to the first page. The result looked like this:
Because a list of ten film titles wouldn’t fit on my phone’s screen after the header, I wrapped the entire screen in a ScrollView component. Since I was just getting started and trying to make sure everything worked, I did not even bother to request enough titles to fill a screen on a larger device, such as a tablet.
Adam Navarro, from the Expo support community, saw my app in the Expo app database when I asked a question, and suggested that I replace the pager buttons with a continuously refreshing, or “infinite”, scrolling list. In other words, when the user enters a new query, the app makes enough requests to fill the screen on whatever device its on, then makes additional requests whenever the user attempts to scroll past the end of what’s already been loaded, until all available results are exhausted. Adam pointed out that I could achieve this easily with the React Native FlatList component.
The FlatList was surprisingly easy to use. At the minimum, you give it an array of items, and a method or component to render each item.
<FlatList
data={films}
renderItem={renderItem}
/>
Optionally, you can pass it a keyExtractor method that will tell it how to obtain a unique key for each list item. Otherwise, your renderItem method or component will have to do that. Since the key property is used only for React bookkeeping and has no bearing on how each list item actually gets rendered, I chose to pass a keyExtractor property to handle it that would be separate from the renderItem method. That’s just how I understand Separation of Concerns. So my FlatList now looks like this:
<FlatList
data={films}
renderItem={renderItem}
keyExtractor={item => item.imdbID}
/>
But there is more goodness in a FlatList. It also takes a ListHeaderComponent, and a ListiFooterComponent property. I assigned it a header component that renders a search bar and displays a little message about how many items were found. I assigned it a footer that shows an animated spinner, or “activity indicator” graphic, whenever the app is loading more items to append the the end of the list, if visible. Otherwise, the footer remains empty. The code now looks like this:
<FlatList
data={films}
renderItem={renderItem}
keyExtractor={item => item.imdbID}
ListHeaderComponent={<Header totalResults={totalResults} />}
ListFooterComponent={<Footer />}
/>
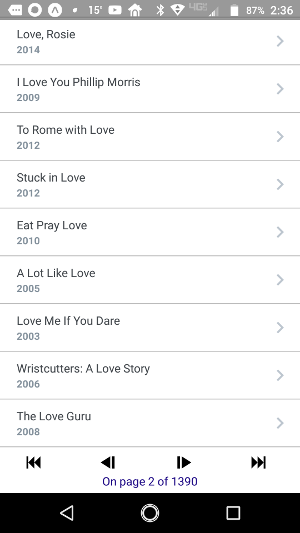
The result looks like this:
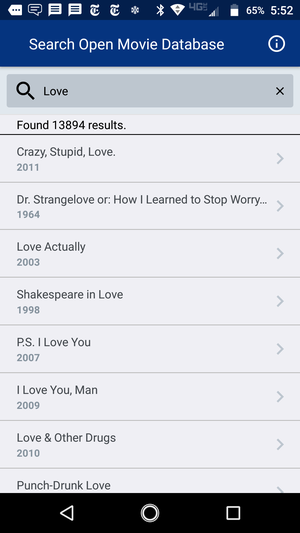
Looking a little better, I think!
Filling the List
But I wasn’t done yet. When the user scrolls to the end of the first ten items it has already fetched and rendered, we want the app to go back more more. dispatchFetchPage() does just that. It makes a remote request to omdbapi.com to fetch ten more film titles from the original query. If all goes well, a response comes back with ten more titles that we append to the list. So the code now looks like this:
<FlatList
data={films}
renderItem={renderItem}
keyExtractor={item => item.imdbID}
ListHeaderComponent={<Header totalResults={totalResults} />}
ListFooterComponent={}
onEndReached={() => dispatchFetchPage()}
/>
So now whenever the user scrolls to the end of the current list, it will automatically fetch and append more items to the list, as long as there are more items to fetch. In fact, some console.log() messages showed that by default the FlatList will invoke onEndReached() several times after it has fetched the first batch of results, and several more times each time the last item scrolls into view. In fact, it seems to begin fetching additional pages even before the last item is visible when it is within a certain distance of being visible.
What if all doesn’t go well? Then the app will display a pop-up with a message like “Unable to fetch data. Try a different title or try again later.” I got it covered!
At this point I expected the end-user experience to be seamless, but I still had work ahead of me. There was a serpent in the garden.

The Silent Treatment
Each list item responds to a press by the user. When the user presses, the app should fetch and display details for the corresponding film, like when it was made, who directed it, who acted in it, etc. But while the app was busy fetching several pages ahead, the app ignored presses for several long seconds, not only on the list items, but also on the back key and the Info icon. I call this The Silent Treatment.
I had trouble understanding why, because once the app makes a remote request, it returns immediately and will end its current cycle and wait for another event, such as a press on a UI component that has already been rendered and is listening for presses. Then I generated console.log() messages from the list item render method and I began to notice that the app was re-rendering every item the list each time it added ten new items. In other words, on the first fetch it rendered 10 items, on the next fetch it rendered 20 items, and so on.
This accounted for the Silent Treatment. React Native runs your code in one thread, while the native UI code runs in a separate thread. They communicate over a pair of incoming and outgoing message queues called the bridge. When the user presses an touchable UI component (any component that is listening for press events), the UI thread responds by enqueueing a message to the JavaScript thread. But that JavaScript thread is non-preemptive. If it is still busy re-rendering a growing number of list items from the top each time, it will stop what its doing to check its incoming queue for new events until it has finished. So the end user keeps pressing and nothing happens for several seconds until the JavaScript thread has finished its work.
But why was the FlatList re-rendering every item in the list from the beginning each time the app appending new items? I had more work to do.
FlatList and Redux
The app uses the Redux store to manage global state variables such as the list of films to be displayed. The Redux documentation is quite clear about the virtue of making the values it manages immutable. “Immutable” in this context means that if your app needs to update a property of an object in the Redux store, it should replace the whole object, not just a single property. Otherwise, if that object is a property ‘p’ of a component, React will compare p to its previous value with ‘===’ (identity comparison), see that p is still a reference to the same object, and will not bother to update re-render that component. This is how React seeks to optimize performance and avoid unnecessarily re-rendering the same components.
So in the stereotypical use-case where we have a list of items to render and we’ve added more items, instead of
newItems.forEach(newItem => list.push(newItem)) return list
our reducer method needs to do this:
return [ ...list, ...newItems ]
In other words, this returns a new array that will be !== list. Note that the original items themselves have not changed. When it is time to test for these items need to be re-rendered, React should see that they are still identical to their previous values and can skip having to re-render them again.
(For those who haven’t yet been exposed to the new ES6 syntax, read this to understand what those ‘…’ ellipses mean.)
But FlatList doesn’t play that way. FlatList is already optimized. It extends VirtualizedList which maintains a finite render window and replaces items that are not visible with blank space in the DOM to preserve memory. The bottom line is that we can let the list itself be mutable. We just don’t want the items in the list to mutate unless there is really something that needs to be rendered differently.
In this case, once the app fetches film titles, each title and its associated data doesn’t change. Reach will render its the virtual DOM for each list item only once and will replace UI DOM items that are scrolled out of visibility with blank space. When it appends additional items it has fetched, it will render only those and not bother to re-render the items that were already in the list.
But if we write our reducer method as I did to return a new immutable list each time it has new items to append, as in
return [ ...list, ...newItems ]
React will notice that the list iteslf is a reference to a different instance or object and will re-render every item from the beginning of the list. As the length of the list increases linearly with each fetch, the so do the number of items to re-render each time it appends new results. The Silent Treatments just get longer and longer from the end user’s point of view.
So the reducer method needs to mutate the list of films as in this example:
newItems.forEach(newItem => list.push(newItem)) return list
When the user enters a new search time and it returns the initial 10 results of a new request, the app starts a new list that is !== to the old one.
return [ ...newItems ]
, so this time React does render the list from the beginning as it should.
The fix was easy, but it was also exactly the opposite of how I thought I’m supposed to write reducer methods for the Redux store. Maybe the doc page for FlatList and VirtualList could be a little clearer on that. I had read them both several times, but I think they could have made this clearer. I am thinking of submitting a pull-request to make this more obvious. We’ll see whether it gets accepted, or whether they tell me I’m just a dunce and should have read more carefully!

More Optimizations
Now things worked much better, but I found some more properties that help optimize the end-user experience. The code now looks like this:
<FlatList
data={films}
renderItem={renderItem}
keyExtractor={item => item.imdbID}
ListHeaderComponent={<Header totalResults={totalResults} />}
ListFooterComponent={}
onEndReached={() => dispatchFetchPage()}
initialNumToRender={8}
maxToRenderPerBatch={2}
onEndReachedThreshold={0.5}
/>
The purpose of initialNumToRender and maxToRenderPerBatch should be obvious. The value of 0.5 for onEndReachedThreshold means that when the last item in the data is within one half of a screen-full of items from being visible, the app should fetch more items. In other words, the app can show about eight items at a time on my phone, so when there are four items left to scroll, the app should start fetching another page. There is a trade-off between fetching ahead enough to keep things moving as the user scrolls, but not so much as to overburden the app so that it will not appear to ignore UI events like presses while it is rendering new items.
There is still a slight lag when the app renders the first page of results until items will respond to presses, but I think that it is now less than a second. There is no search button, the app begins requesting titles 300ms after the user pauses or stops typing. Therefore, a lag of less than a second before the UI will respond to screen presses should not be an issue for all but those with very fast fingers. I did not set any timers to check the actual lag because I’m more concerned with the perception of UI responsiveness than the actual value in milliseconds. If it feels slow, then it is slow.
Subsequent fetches do not seem to produce any lag at all, so I think I achieved my goal of providing a smooth UX/UI experience on the Search Results page.
Conclusion
The FlatList component was announced in March of 2017 so it has been around for a little over a year at the time of this writing. It is a very powerful component for rendering large lists of items efficiently, but it’s also complicated. It takes all the same properties as the VirtualizedList and the ScrollList combined, plus it adds a dozen or so of its own properties, so it probably takes at least 50-60 properties. It takes some experience and knowledge to use it effectively for a smooth UI experience.
In particular, if its data property comes from the Redux store, you want to be sure not to replace that list each time you have more items to append to it, because doing so will defeat the FlatList’s ability to render only new items in the React Virtual DOM. Instead, as the FlatList and VirtualList documentation suggests, make sure that the list items are immutable and that the list-item component extends React.PureComponent which is a contract that promises that the rendered state of a component depends only on a shallow comparison of its properties.
]]>